Splitting Learning from Constraint: Designing AI-Augmented Teams
How to separate learning capture from enforcement when LLMs make both cheap
You’ve probably felt it: your team is moving faster than ever with LLMs. More code, more prototypes, more ideas in a week than you used to get in a month.
Yet somehow confidence isn’t rising. The same kinds of mistakes repeat. Old “rules” linger long after the context that created them has changed. And new insights seem to vanish as quickly as they appear.
This isn’t because people aren’t smart or trying hard enough. It’s a systems problem—one Agile solved brilliantly for its era, and one we now need to solve differently in ours.
Agile and Extreme Programming solved this once, for a different era. They worked because their practices forced learning and behavior change to happen at the same time. Tests, pairing, short iterations, standups. Each practice did double duty. You did not just notice a problem. You were constrained to work differently immediately.
That coupling made sense when feedback was hard to get, enforcement was social, and memory lived in people’s heads.
Today, that same coupling breaks down.
Exploration is cheap. Artifacts multiply instantly. Some mistakes can’t be undone—the path closes behind you. Rules can be enforced automatically. Knowledge can be stored, searched, and replayed.
When learning and constraint stay glued together in this environment, teams hit two predictable failure modes.
The core issue is not that teams learn the wrong things. It is that they lose control over when learning turns into rules.
In Agile, the only durable place to store learning was inside practice. That made sense when memory was fragile and informal. In an AI world, it means every insight is forced to act like policy, and every policy pretends to be wisdom.
First, rules harden too early. A local failure becomes a global policy. A painful incident turns into doctrine. Yesterday’s scar tissue blocks today’s exploration.
Second, rituals persist while learning disappears. Standups happen, nothing changes. Tests exist, design does not improve. Retros run, decisions do not move. The practice remains. The feedback loop is gone.
You’ve seen it play out: a caching strategy suggested by an LLM blows up in production once. Suddenly “no dynamic caching” becomes unspoken doctrine—even as traffic patterns change and the original failure’s lessons fade into folklore.
This is not a team maturity issue. It is structural.
The way out is not “smarter AI” or “better prompts.” It is splitting roles that Agile had to collapse.
Think of traditional Agile practices as wet cement: you had to shape learning into a permanent mold immediately or it would be lost. In an AI world, the cement sets too fast—old molds become rigid walls that block new paths. The shift is to keep learning fluid longer while still building strong, explicit constraints where they’re truly needed.
The split only becomes clear when LLMs are given distinct jobs, not general intelligence.
LLMs are bad at judgment.
That is not a flaw. It is a constraint you can design around.
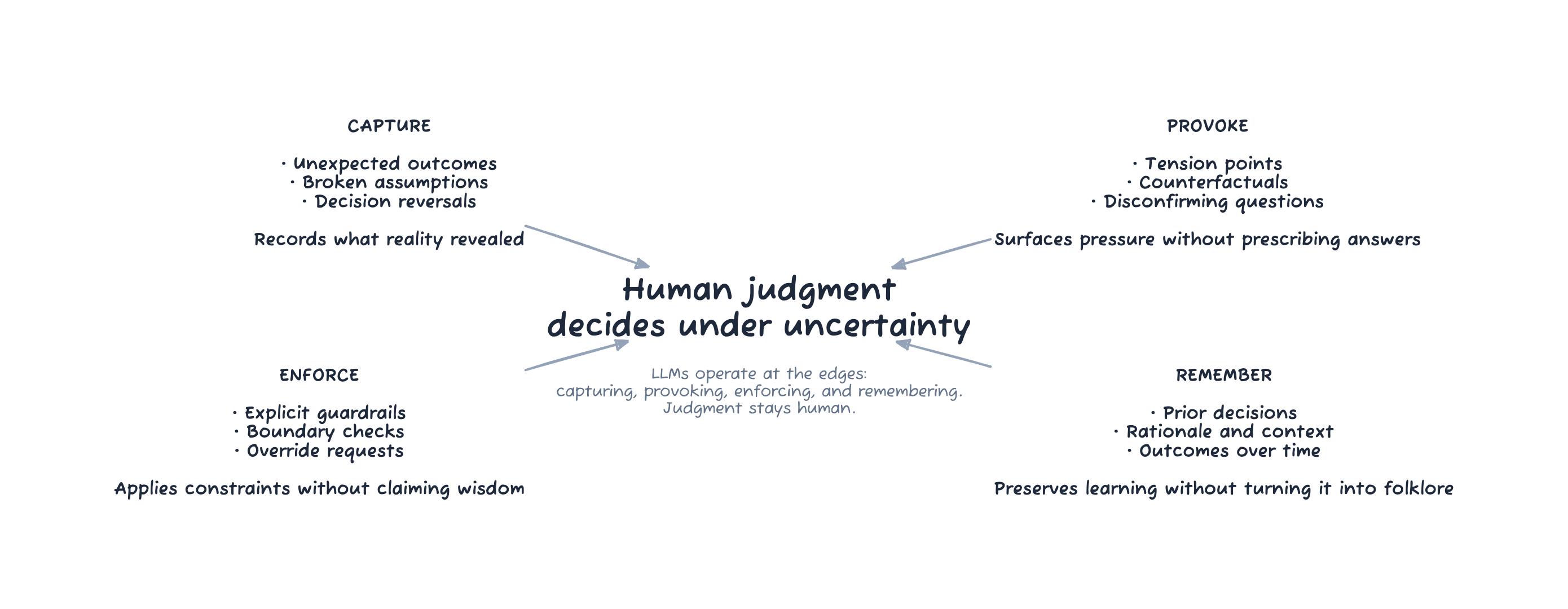
The Key Move: Give LLMs Asymmetric Roles
They are weak at judgment, but strong as recorders, provokers, enforcers, and librarians.
Agile collapsed learning, constraint, enforcement, and memory into single practices because it had to. We no longer do.
Instead of giving the model general intelligence, give it four narrow, asymmetric jobs that keep human judgment firmly in the center:
- Recorder: captures learning without authority
- Enforcer: checks explicit constraints and requests justification for overrides
- Provoker: asks the uncomfortable, Socratic questions that surface risk and assumptions
- Librarian: preserves durable memory so learning compounds
1. Capture Learning Without Authority
LLMs are very good at noticing contradictions, summarizing surprises, extracting decisions and rationales, and turning messy logs into structured notes.
Use them to:
- harvest what surprised you
- record what broke expectations
- log why decisions changed
- capture what only became obvious after action
Critically:
- they do not decide what to do next
- they do not turn insights into rules
This is how learning stays plastic. It can accumulate without freezing into policy.
The Promotion Gate: When Does Learning Become a Rule?
The split only works if there is a deliberate “promotion gate” between what you learn and what you enforce.
Captured learning should live as low-authority memory: incident summaries, decision rationales, “here’s what surprised us” notes—informative but not binding, and not enforceable without promotion. It is searchable, revisitable, and allowed to be messy.
Constraints are different. They are explicit, scoped, and enforced on purpose.
A useful default: a rule only becomes enforceable when a human can write down:
- the boundary (what’s in vs. out)
- why it exists (the failure mode or risk it prevents)
- when it should be revisited (a sunset date, a signal, or an owner)
If you can’t state those three, keep it as learning, not policy.
That third criterion matters more than it looks. Most organizations are good at adding rules and terrible at retiring them. Without a revisit mechanism, constraints turn into stale scar tissue.
Common promotion triggers:
- repetition: the same failure mode appears a second or third time (a first recurrence should trigger a question, not a new constraint)
- irreversibility: a mistake is hard to unwind (data loss, lock-in, regulatory risk)
- high leverage: a small constraint prevents a large class of harm
- onboarding: new teammates keep rediscovering the same edge case
Corollary: if a mistake is cheap to unwind, keep it as learning longer. Capture it, let the Provoker surface it next time, and only promote it if it keeps repeating or becomes irreversible.
Crucially, promotion is an intentional team act, not an automatic side effect of an incident. The model can draft a candidate rule, but humans decide whether it becomes an enforceable constraint.
2. Enforce Rules Without Pretending They Are Wisdom
Separately, LLMs can enforce explicit constraints that have been deliberately promoted from learning into policy.
They can:
- check whether stated constraints were followed
- ask for justification when they were not
- block obvious violations
This is enforcement, not judgment.
The model does not say “this is wrong.” It says “this violates an agreed boundary, explain why.”
Overrides are allowed, but they require explanation. That explanation becomes new learning input (and sometimes the seed of a future constraint). Enforcement creates pressure. It does not claim insight.
This breaks from Agile’s reliance on social enforcement without drifting into rigid bureaucracy.
3. Bias Questions, Not Answers
This is the Provoker role: a model whose job is to ask better questions, not to decide. The model should not recommend actions. It should surface pressure points based on past experience.
Questions like:
- “Last time, this kind of change caused irreversible lock-in. What is different now?”
- “You are committing earlier than usual. What uncertainty has been resolved?”
- “Which assumption, if wrong, breaks this whole plan?”
This preserves learning pressure without prescribing behavior. It makes teams pause without telling them what to do.
4. Use Durable Memory So Learning Compounds
Agile assumed teams would remember. Context would carry forward. Learning would survive turnover.
This is the Librarian role: a model-plus-storage system whose job is to preserve context over time so teams don’t keep relearning the same lessons.
That assumption breaks under modern conditions: teams scale, people rotate, context-switching increases, and rationale disappears into tickets, PRs, and chat.
LLMs plus storage let you:
- persist lessons without ossifying them
- decay old learning instead of deleting it
- revisit rationale instead of folklore
- distinguish “this happened once” from “this keeps happening”
Memory becomes explicit, searchable, and reviewable. Learning compounds instead of resetting every few months.
What This Is Not
This is not AI making decisions. It is not AI doing strategy. It is not AI inventing rules. It is not replacing disagreement or trade-offs.
Humans still decide. Humans still take risk. Humans still own judgment.
The system simply makes learning cheaper to capture, constraints clearer to enforce, and memory harder to lose.
What This Looks Like in Practice
A team makes a decision. Something unexpected happens. An LLM captures what broke expectations and why the decision changed. No rule is created.
Example: A team deploys a new caching strategy suggested by an LLM. It causes unexpected latency spikes in production. The post-incident LLM summary captures: “Assumption about traffic patterns was wrong; invalidation logic didn’t account for X.” No new rule is created. Six weeks later, when a similar pattern appears in a PR, the Provoker model asks: “This matches a prior invalidation failure. What’s different this time?” The team explains why it’s different this time. That justification feeds back into memory.
If the pattern keeps repeating—or the risk is high enough to justify hardening it into a constraint—the team promotes an explicit constraint using the promotion gate.
From then on, the Enforcer runs a constraint check. The constraint applies, or it is overridden with explanation.
The next time, the system asks sharper questions earlier.
That is the loop: capture → accumulate → (sometimes) promote → enforce → override → feed back.
Learning stays separate from constraint. Constraint stays explicit. Enforcement stays proportional. Memory stays alive.
Why This Matters
Agile taught us the power of fast feedback. LLMs change the economics of exploration, memory, and enforcement.
That makes a new operating model possible.
One where:
- learning does not instantly freeze into process
- rules do not pretend to be wisdom
- enforcement does not rely on meetings
- insight survives success, failure, and turnover
The question now is not how to go faster.
It is whether we are willing to design systems where learning can keep moving, without freezing into rules too early.
That is the real evolution Agile needs in an AI world.
Comments powered by Disqus.